Rainfall Predictor

Designed and developed supervised Machine Learning models for predicting rainfall at a particular location. The project was carried out by 2 awesome teammates and myself, in hopes of getting a good grade on Prof. Sameer Singh‘s course of Machine Learning.
The data
Courtesy of the UC Irvine Center for Hydrometeorology and Remote Sensing, our data consisted of satellite-based measurements of temperature at particular locations across the globe (infrared imaging) and information about clouds (such as area and average temperature). Each data point corresponded to a location on the globe (identified by its latitude, longitude and elevation) and was labeled with CHRS’s belief of whether that particular location will admit rain.
Approaches
We tried the following models:
- Neural Networks and Deep Learning
- Random Forests
- Support Vector Machines
Random Forests turned out to be the model scoring highest in validation AUC, with scores above 0.79. We used hold-out validation with a training fraction of 80% of the data.
Experiments were carried out using scikit-learn's
implementations of Random
Forests (both RandomForestRegressor and ExtraTreesRegressor) and we
experimented different configurations of the following parameters (see code at
the end):
max_depth. The maximum depth on all the decision trees. IfNone, the depth is unrestrictedmin_samples_split. The minimum number of samples to split a node (e.g. minParent)min_samples_leaf. The minimum number of samples to form a leafmax_features. The maximum size of the subsample of features considered in splittingn_estimators. The number of decision trees generatedbootstrap. Either True or False. Inscikit-learn, the subsample of the data (drawn with or without replacement) will always have the size as the data itself
Random Forest Results
In the end, an unlimited max_depth together with small sizes of feature
subsampling (max_features=2) and a large number of decision trees
(n_estimators=300) turned out to be a very good configuration of params. The
remaining parameters revealed little influence in validation AUC. See below for
a plot of training and validation AUC’s varying max_features and
n_estimators, with and without bootstrap.
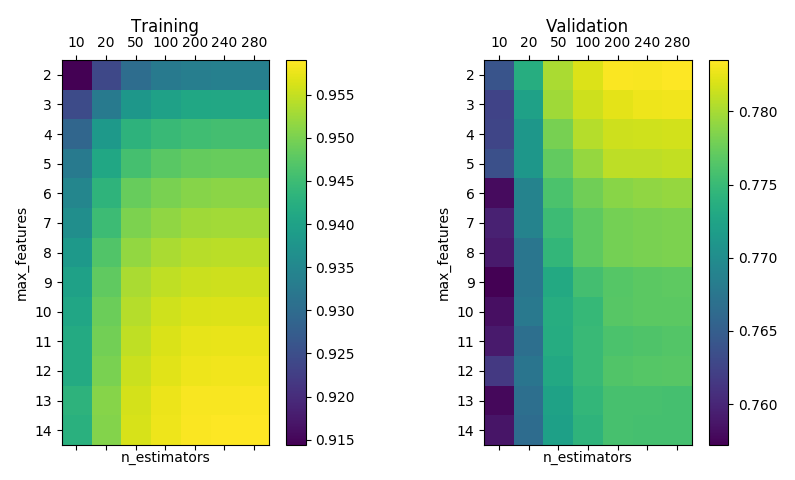
RandomForestRegressor with bootstrap, min_samples_split=min_samples_leaf=5 and max_depth=None.
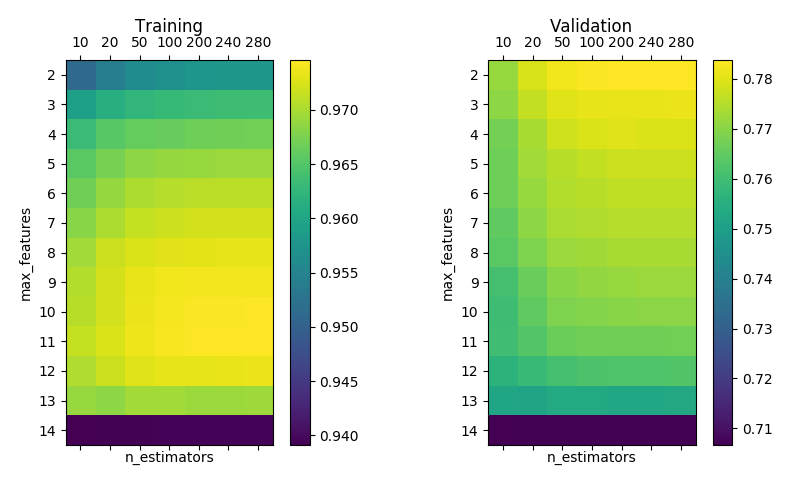
RandomForestRegressor without bootstrap, min_samples_split=min_samples_leaf=5 and max_depth=None.
The following plots are similar to the ones above, but using
ExtraTreesRegressor instead, where in addition to using a random subset of splitting candidate features, it samples a random subsubset from this subset when evaluating the most discriminating splitting feature.
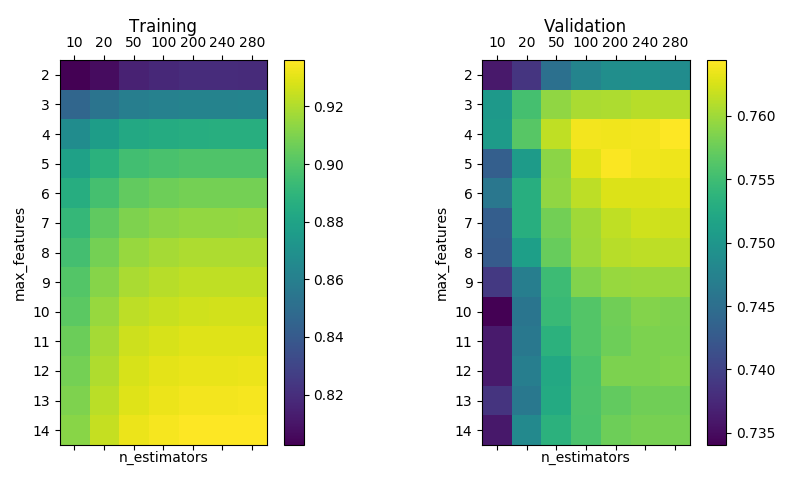
RandomForestRegressor with bootstrap, min_samples_split=min_samples_leaf=5 and max_depth=None.
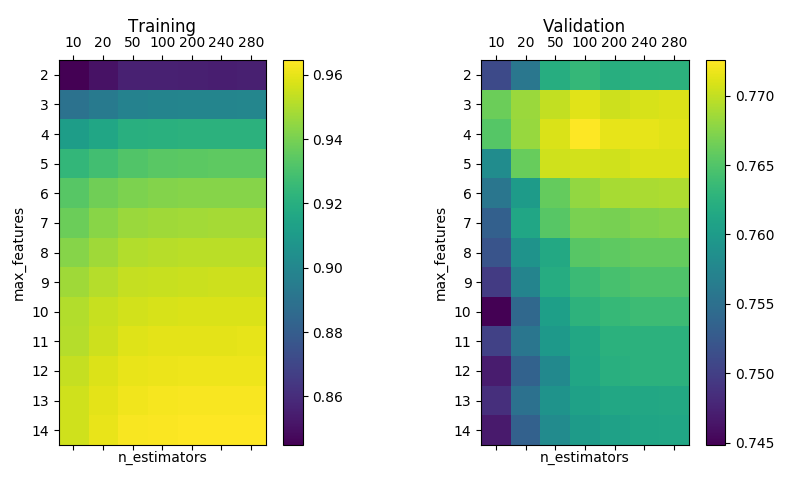
RandomForestRegressor without bootstrap, min_samples_split=min_samples_leaf=5 and max_depth=None.
Random Forests code
# Consistent behavior
np.random.seed(0)
def loadData(filename):
""" Load data from binary cache if possible for efficiency. """
f = os.path.splitext(filename)[0] + '.npy'
if os.path.isfile(f):
D = np.load(f) # faster than genfromtxt
else:
D = np.genfromtxt(filename, delimiter = None)
np.save(f, D)
return D
def gen_params(**params_ranges):
params_ranges = {k: [(k, v) for v in params_ranges[k]] for k in params_ranges}
return map(dict, itertools.product(*params_ranges.values()))
if __name__ == '__main__':
timestamp = str(int(time.time()))
# Prepare output folder for results
date = datetime.fromtimestamp(time.time()).strftime('%m-%d_%H-%M-%S')
# Data Loading
X = loadData('data/X_train.txt')
Y = loadData('data/Y_train.txt')
X, Y = ml.shuffleData(X,Y)
m, n = X.shape
Xtr, Xva, Ytr, Yva = ml.splitData(X, Y)
Xt, Yt = Xtr, Ytr
max_depth = [None]
min_samples_split = [10]
min_samples_leaf = [10]
max_features = [2]
n_estimators = [100]
bootstrap = [True]
type = ['RF']
params_ranges = {p: eval(p) for p in ['max_depth',
'min_samples_split',
'min_samples_leaf',
'max_features',
'n_estimators',
'bootstrap',
'type']}
results = []
for params in gen_params(**params_ranges):
t = params.pop('type')
if t == 'RF':
RF = RandomForestRegressor(n_jobs = -1, random_state = 0, **params)
else:
RF = ExtraTreesRegressor(n_jobs = -1, random_state = 0, **params)
RF.fit(Xt, Yt)
params['AUCt'] = roc_auc_score(Yt, RF.predict(Xt))
params['AUCv'] = roc_auc_score(Yva, RF.predict(Xva))
params['type'] = t
results.append(params)
if saveResults:
with open('experiments/' + timestamp + '.json', 'w') as f:
json.dump(results, f, indent = 2)