dbms
Language: C++11
Built my own database management system from scratch, with the help of a teammate. This project was in the scope of the class “Principles of Data Management”, at UC Irvine, and was divided into the following parts:
- Disk I/O Page-Based Manager
- Record-Based File Manager
- Relation Manager
- Index Manager
- Query Engine
1. The Disk I/O Page-Based Manager
- Provides higher-layered managers with tools to perform I/O operations in terms of pages (eg: open/close file, create/destroy file and read/write pages to the file).
2. Record-Based File Manager
- Responsible for inserting, deleting and updating records within a given page-based file. Records are identified and located within a file by a pair
(pageNumber, recordSlot)calledRID. - The attribute types supported are:
INT,REALandVARHCAR(N). Thus, variable-length records are possible. - It has the responsibility of managing the free space offset within a page and guarantee $O(1)$ time for accessing the $i^{th}$ attribute of the record. For this reason, both pages and records are encoded in disk with a specific format chosen by the manager itself.
3. Relation Manager
- Responsible for managing the database tables (creating/deleting tables and inserting/removing tuples)
- It keeps database schema in the system catalog, which is itself a table
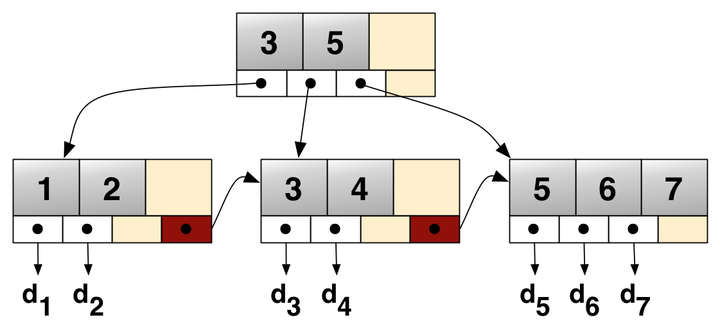
4. Index Manager
- Implemented using a B+ Tree that supports all the necessary operations: insertion, removal, key lookup and range scan.
- Every node in the tree, intermediate or leaf node, corresponds to a page of size 4096 bytes and it must be at least half full – requirement for B+ trees to reduce sparsity and fragmentation.
- For simplicity, we don’t care about keeping the above property whenever deleting a record. This is because merging nodes is a complex task (splitting in insert are simpler) and deletes are not frequent.
5. Query Engine
- Provides the functionality to answer SQL queries
- The following relational operators were implemented:
- Filter
- Projection
- Aggregate (with “Group by”)
- Join, using:
- Block-Nested Loop Join
- Index-Nested Loop Join